“统计大讲堂”第196讲回顾:用噪声对抗噪声:多候选工具变量的因果推断
2022-07-18
6月29日下午,“统计大讲堂”系列讲座第196讲举行。本次讲座采取线上会议的方式,邀请多伦多大学统计学助理教授孔德含作题为“Fighting Noise with Noise: Causal Inference with Many Candidate Instruments”的报告。讲座由尊龙凯时平台研究员🏠👨🏼🦱、统计学院教授许王莉主持👥。

许王莉首先介绍了主讲人的相关信息🧑🏽⚕️。孔德含🚪,多伦多大学统计学助理教授,现任美国统计学会会刊副主编🚶🏻♀️。研究方向包括脑图像,函数型数据分析🏃🏻➡️,因果推断🙍,高维数据分析以及机器学习。
孔德含首先从生活中的超重这一普遍现象引入工作目标“超重是否会影响人的生活质量”🦀,即用BMI衡量是否超重,研究BMI与生活质量之间的因果关系。但在这种情况下,会有一些混淆因素,如人的生活习惯👶🏼,它会对BMI和生活质量造成不同影响🥃。想要得到BMI与生活质量间的因果效应,就需要通过outcome等模型去校正这些混淆变量。而实际生活中🍚,这些混淆因素往往不能都观测到,因此没有办法通过校正混淆因素的方式得到因果效应的估计。随即🤵🏿,孔德含介绍了Mendelian randomization(MR)方法来解决上述问题。若通过一个随机试验(如用人的基因型进行区分)得到的一串随机的BMI值🧚♀️🧑🏿🏫,它们就不会被后天的混淆因素所影响。
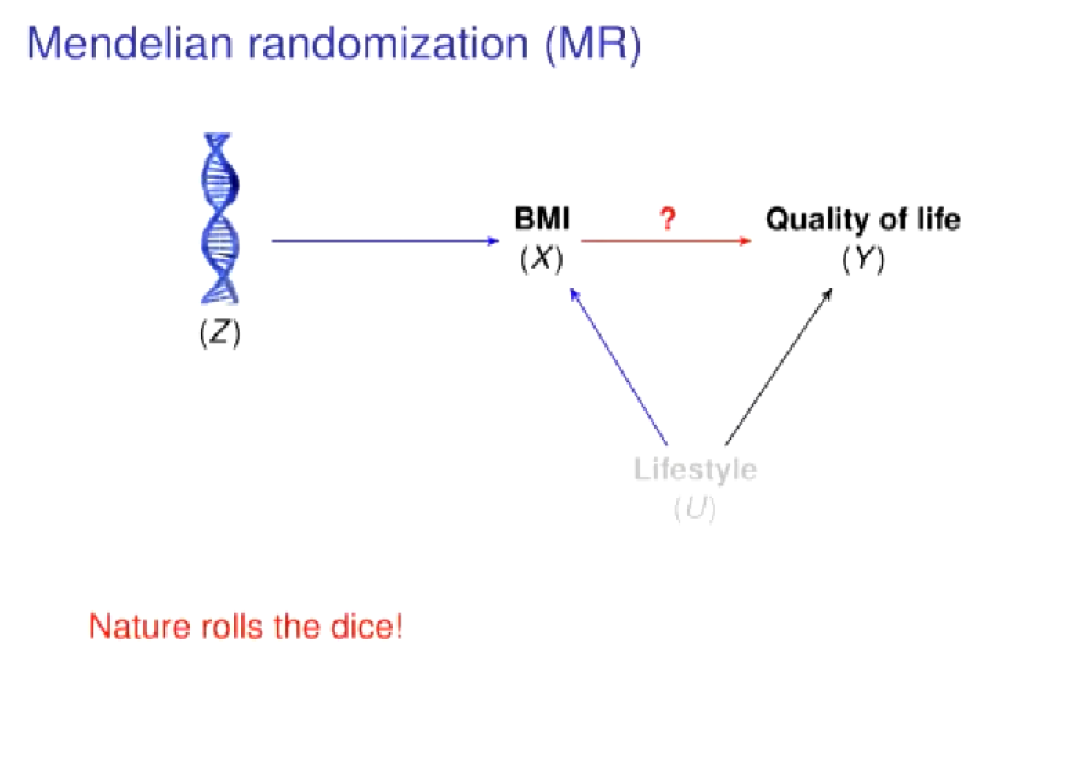
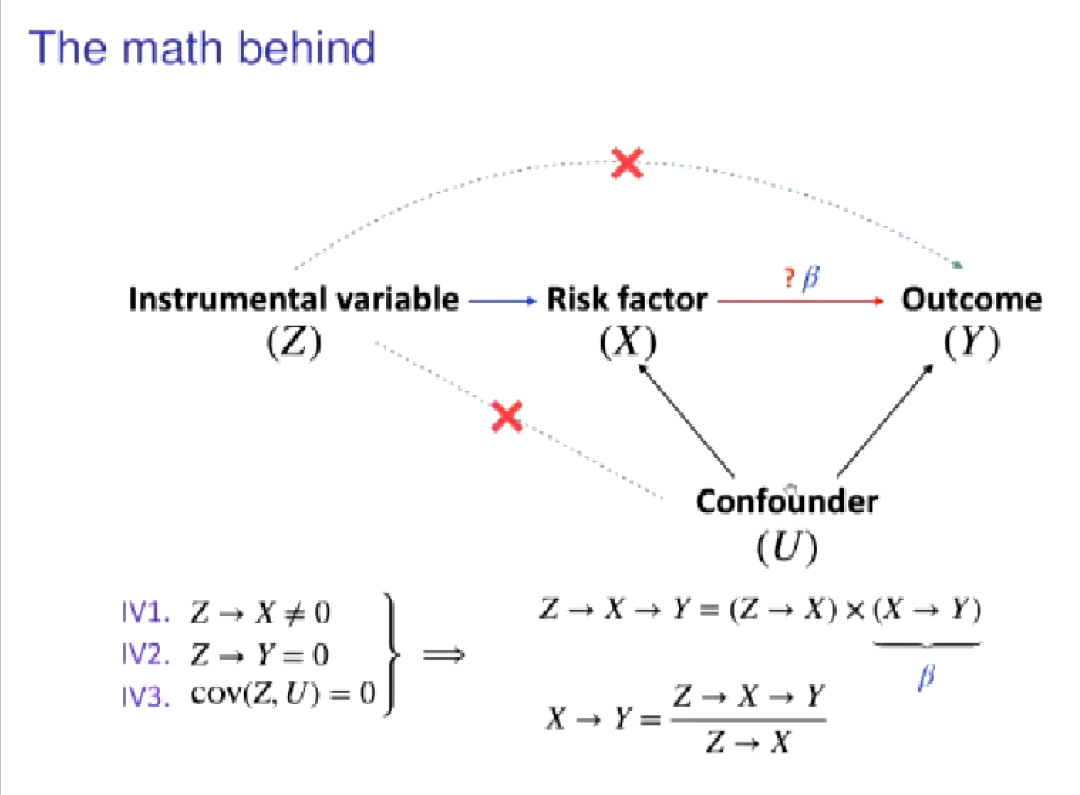
接着👩🏭,孔德含对因果推断的结构作了简单介绍。其中风险因素为X🧎🏻➡️,结果为Y,从X到Y的红线为X到Y的因果效应🕣,因果效应的真值为β,混淆因素为U🧑🤝🧑👏🏽,工具变量为Z。工具变量在混淆因素没有观测到的情况下使用,需满足三个条件🚴,一是必须影响X,二是不能直接影响Y,三是与U之间不能存在相关性。这样,X到Y的因果效应就能写成一个比例🥁,称为wald ratio👟,在有限样本的情况下,该比例的估计称为two stage least squares📃。
孔德含指出👂,自然实验并不完美🙇🏿♂️。一是绝大多数基因型变量Z是无关的,如果想知道基因型与X相关,需使用GWAS分析🏝。二是即使是相关的Z也可能无效。若一个基因的变种会影响多个特征🧜🏻♂️,那么该基因可能是无效的。现存的方法分为三个步骤:第一步🏌️,通过GWAS找到与X相关的Zj🦺;第二步🙏,用mode- finding算法识别有效工具变量;最后一步,使用这些识别出来的有效工具变量进行因果效应估计。随后他举出一个模拟例子对上述三步加以运用,并分析了模拟中存在的问题及解决方法🥍。

针对工具变量⏱🚵🏼♂️,孔德含介绍了用于分开无关和有效工具变量的两条理论⛹🏽♀️。第一条,如果无关工具变量被选进来,那么它们的因果效应的估计就在一个含参区间内;第二条,对有效的工具变量😑,若概率趋于1,其因果效应的估计就集中于β*,即若d小于|C*|或U尽可能大或ω尽可能大🔂,则伪变量与有效变量可以分开🪞。

在演讲最后🫅,孔德含对所述研究中使用的数据进行了说明与讨论,并作了简要总结。

在提问环节中,孔德含认真细致地解答了师生们的疑问📽,就本话题进行了更进一步的探讨。